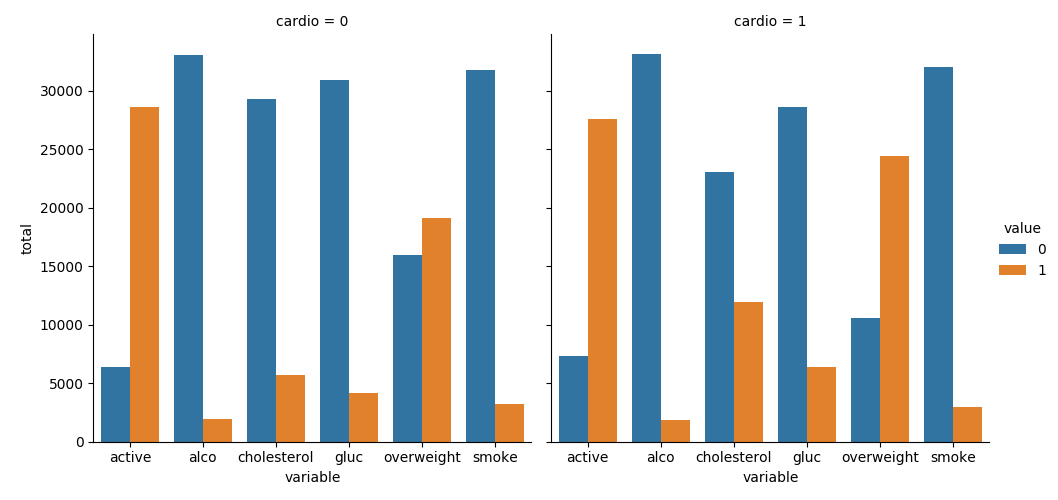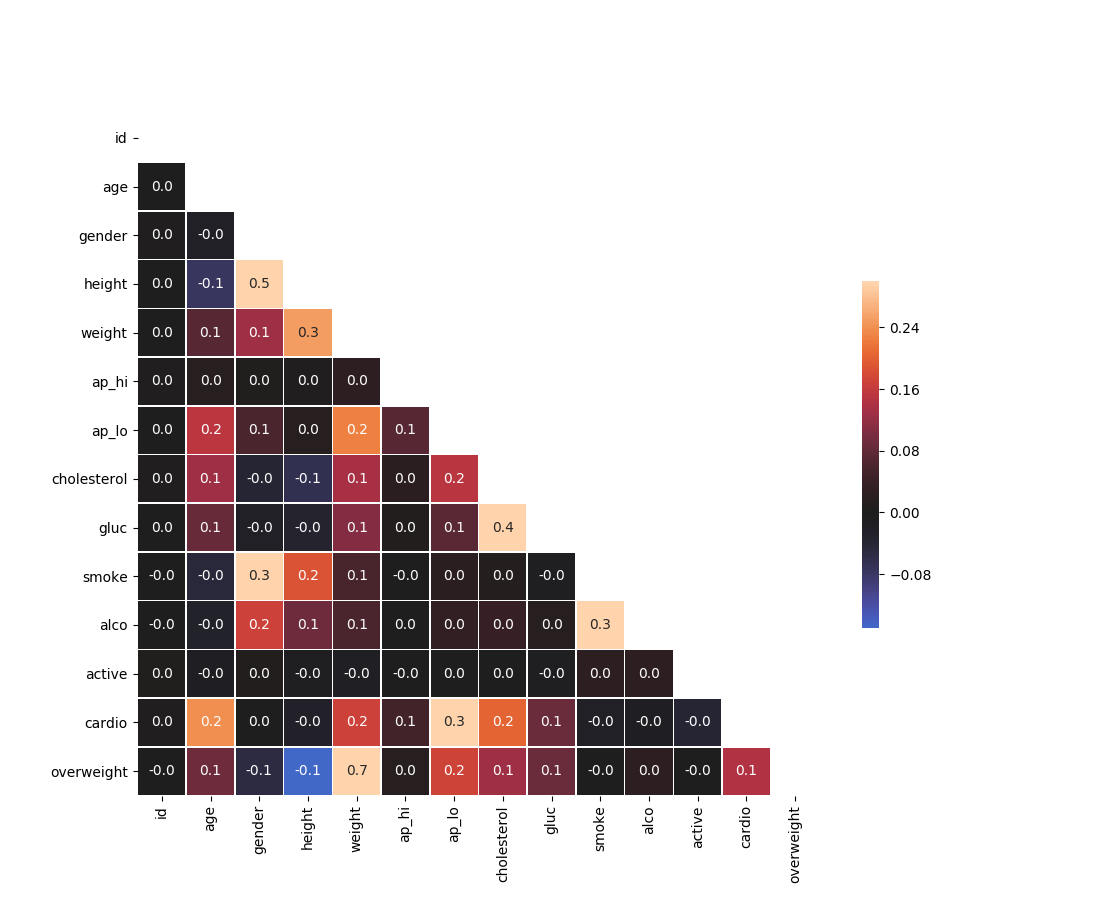
O objetivo deste projeto é explorar a relação entre doenças cardíacas, medidas corporais, marcadores sanguíneos e escolhas de estilo de vida. O conjunto de dados foi coletado durante exames médicos. Foram utilizadas as bibliotecas matplotlib, seaborn e pandas para visualizar e realizar cálculos a partir do dados de exames médicos.
Descrição dos Dados
As linhas no conjunto de dados representam pacientes, e as colunas representam informações como medidas corporais, resultados de vários exames de sangue e escolhas de estilo de vida. A base de dados pode ser consultada na seção Base de Dados.
Aqui está uma breve descrição das colunas presentes na base de dados:
| Característica | Tipo da Variável | Variável | Tipo do Valor |
|---|---|---|---|
| Idade | Característica Objetiva | age | inteiro (dias) |
| Altura | Característica Objetiva | height | inteiro (cm) |
| Peso | Característica Objetiva | weight | fracional (kg) |
| Gênero | Característica Objetiva | gender | código categórico |
| Pressão Arterial Sistólica | Característica de Exame | ap_hi | inteiro |
| Pressão Arterial Diastólica | Característica de Exame | ap_lo | inteiro |
| Colesterol | Característica de Exame | cholesterol | 1: normal, 2: acima do normal, 3: muito acima do normal |
| Glicose | Característica de Exame | gluc | 1: normal, 2: acima do normal, 3: muito acima do normal |
| Tabagismo | Característica Subjetiva | smoke | binário |
| Consumo de Álcool | Característica Subjetiva | alco | binário |
| Atividade Física | Característica Subjetiva | active | binário |
| Presença ou Ausência de Doença Cardiovascular | Variável Alvo | cardio | binário |
Etapa Inicial
Importação de Bibliotecas
O código começa importando as bibliotecas necessárias: Pandas para manipulação de dados, NumPy para operações numéricas, Matplotlib para visualizações básicas e Seaborn para visualizações estatísticas mais avançadas.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Base de Dados
Carregar base de dados
medical_data = pd.read_csv('medical_examination.csv')
Aqui temos uma pequena visualização dos valores presentes na base de dados. Apenas os primeiros 5 valores serão imprimidos.
# Imprime os primeiros valores
print(df.head())
| id | age | gender | height | weight | ap_hi | ap_lo | cholesterol | gluc | smoke | alco | active | cardio |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 18393 | 2 | 168 | 62.0 | 110 | 80 | 1 | 1 | 0 | 0 | 1 | 0 |
| 1 | 20228 | 1 | 156 | 85.0 | 140 | 90 | 3 | 1 | 0 | 0 | 1 | 1 |
| 2 | 18857 | 1 | 165 | 64.0 | 130 | 70 | 3 | 1 | 0 | 0 | 0 | 1 |
| 3 | 17623 | 2 | 169 | 82.0 | 150 | 100 | 1 | 1 | 0 | 0 | 1 | 1 |
| 4 | 17474 | 1 | 156 | 56.0 | 100 | 60 | 1 | 1 | 0 | 0 | 0 | 0 |
O conjunto de dados completo pode ser encontrado em:
Resultados